Mastering Yahoo Search Engine Scraping with R: A Guide
Written on
Introduction to Web Scraping
Web scraping refers to the method of automatically extracting data from websites. This technique allows users to gather extensive data from various online sources without the need for manual collection. In a previous article, we explored web scraping using a Wikipedia page as a reference. While web scraping has numerous applications, this guide will specifically focus on scraping Yahoo search results using R. This can be particularly beneficial for SEO analysis, competitor insights, keyword exploration, and trend evaluation.
Getting Started with Yahoo Search Engine Scraping
To begin scraping Yahoo search results, you must first install R and RStudio. The subsequent step involves loading the required packages by executing the following commands:
# install.packages("rvest")
# install.packages("jsonlite")
# install.packages("purrr")
library(rvest)
library(jsonlite)
library(purrr)
The rvest package is dedicated to web scraping, while jsonlite assists in handling JSON data, and purrr is utilized for functional programming with vectors.
Before diving into scraping, it's essential to determine the specific data points of interest. For this tutorial, we will extract search results from the following URL:
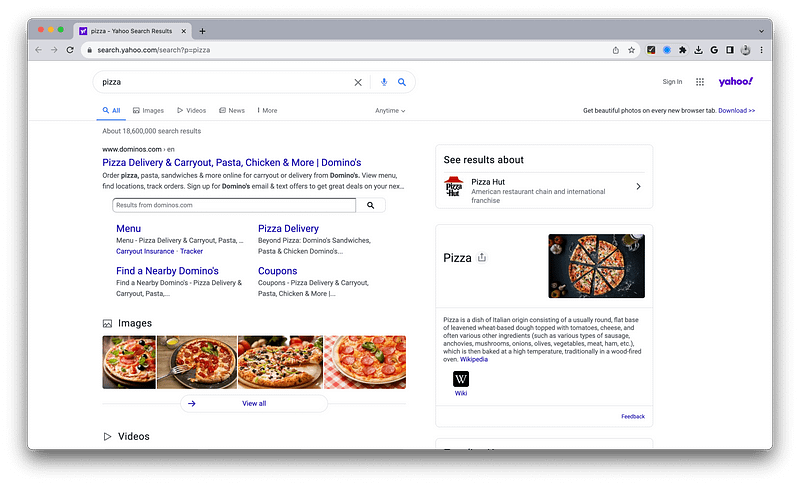
Data Points to Scrape
We aim to capture the following elements from the search results:
- Link
- Title
- Description
To initiate this, we will define the URL for our Yahoo search results, specifically searching for "pizza":
# URL of the Yahoo search results page
Next, we will utilize the read_html() function from the rvest package to retrieve the HTML content of the specified URL:
# Read the HTML content of the page
page <- read_html(url)
This command generates an HTML document object for further processing:
str(page)
Now, let's extract the search results:
# Extract search results
results <- page %>%
html_nodes(".algo-sr") %>% # Selector for search result elements
html_nodes("a") %>% # Select the <a> elements within the search results
# Extract link, title, and description attributes
map_df(~ data.frame(
link = .x %>% html_attr("href"),
title = .x %>% html_text(),
description = .x %>% html_attr("title"),
stringsAsFactors = FALSE
))
In this code snippet:
- We utilize the pipe operator %>% for streamlined processing.
- The html_nodes(".algo-sr") function selects elements associated with search results.
- We then drill down to the <a> elements, which contain relevant information.
- Using map_df(), we iterate through each <a> element to extract the link, title, and description attributes, compiling them into a data frame.
Finally, we convert the results data frame to JSON format, using the toJSON() function from the jsonlite package. The pretty = TRUE argument formats the output for enhanced readability. We can display the JSON data in the console with:
# Print the results in JSON format
cat(toJSON(results, pretty = TRUE))
Conclusion
Thank you for engaging with this tutorial. We have demonstrated how to scrape Yahoo search results using R. By following this process, you can develop your own web crawler to gather search results for any query on Yahoo. The same methodology can be applied to scrape data from other search engines as well. For additional insights, consider reviewing our tutorial on scraping Google search results using Python.
If you have any questions or suggestions regarding this article, please feel free to leave a comment to enrich the discussion for other readers.
As a reminder, always ensure that any R package is installed using the install.packages() function before loading it with library().
Learn how to extract stock index components from Yahoo Finance using R in this informative video.
This video guides you through scraping Yahoo Finance data and performing time series analysis with R Studio.