Unlocking Jupyter Notebooks: 4 Essential Features for Data Science
Written on
Introduction to Jupyter Notebook Features
The Jupyter Notebook serves as a powerful tool for data scientists, enabling us to visualize data through text and graphics while we conduct data processing and analysis. Once we grasp the fundamental operations of the Notebook, we can explore additional features that can significantly enhance our experience and productivity. This article presents several key functionalities that cater to specific requirements in our data science tasks.
Running Commands Efficiently
To execute commands within cells, you can simply add an exclamation mark before the command.
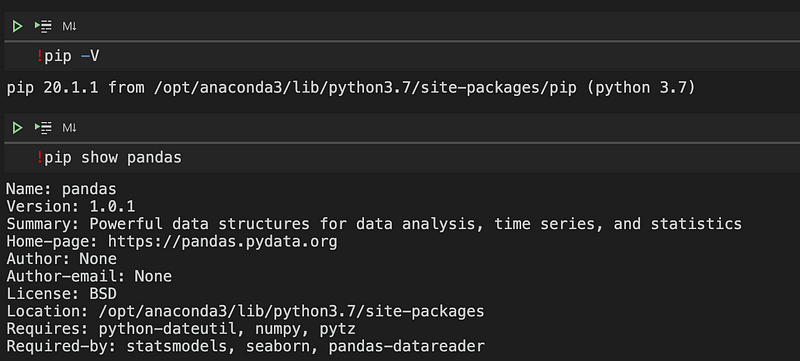
A common query related to command execution is how to handle prompts, such as installation confirmations. A useful tip is to append the yes flag (-y) to your command, as demonstrated below: !pip uninstall seaborn -y
Checking Active Variables
When handling extensive datasets, it's easy to accumulate numerous intermediate variables. To get an overview of the current variables in your workspace, you can use the magic commands %who or %whos, with the latter providing more detailed information.
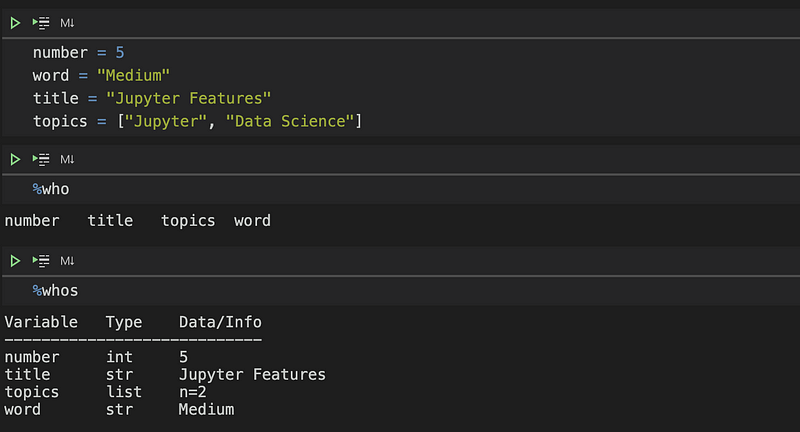
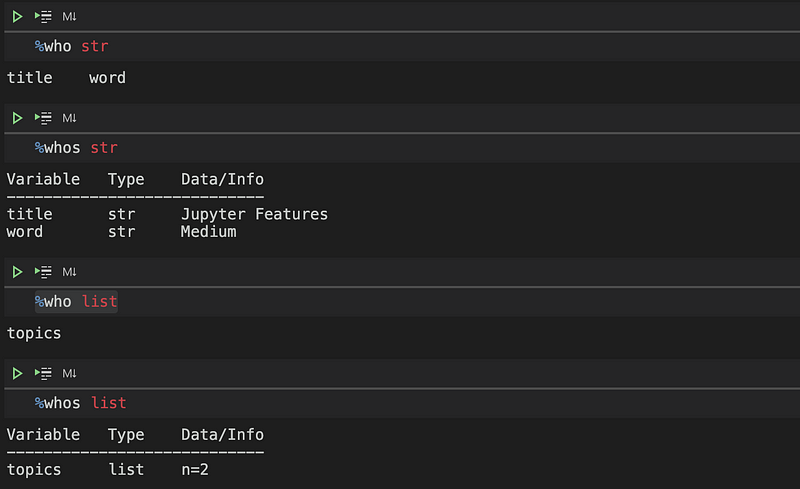
To refine this command, you can specify the data type of the variables, resulting in a more concise list. For example, the following command displays only string-type variables:
API Lookups for Quick Reference
It's common to forget certain functions or attributes we wish to use. However, we can jog our memory by listing related methods.
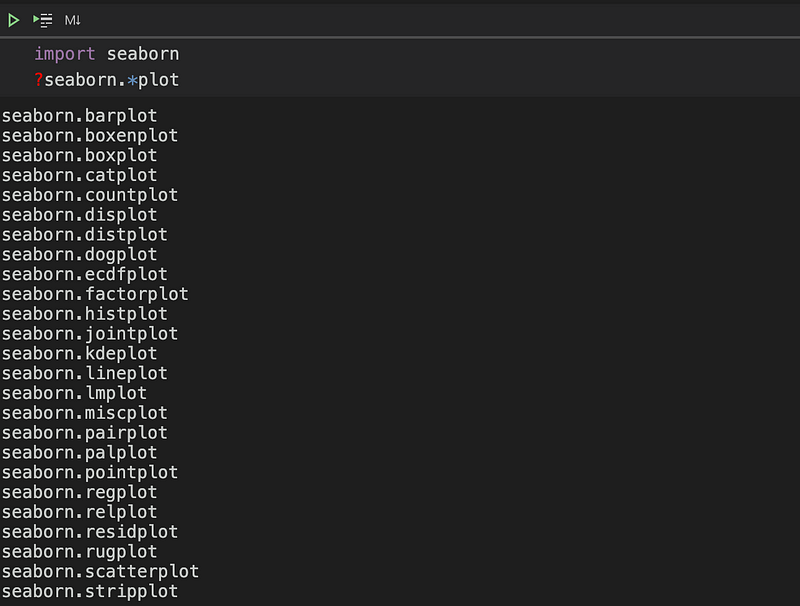
For example, if you're interested in the available plots in the seaborn package, you can simply use a wildcard with a question mark. Once you've identified the method you want to use, you can check its calling signature by using the question mark followed by the function name:
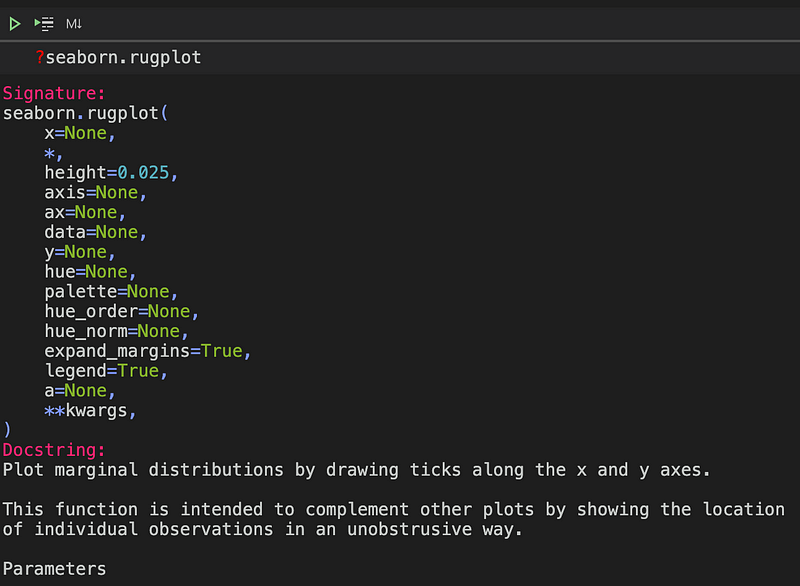
This output is akin to what you can achieve with the help function, for example: help(seaborn.rugplot)
Changing Default Output Behavior
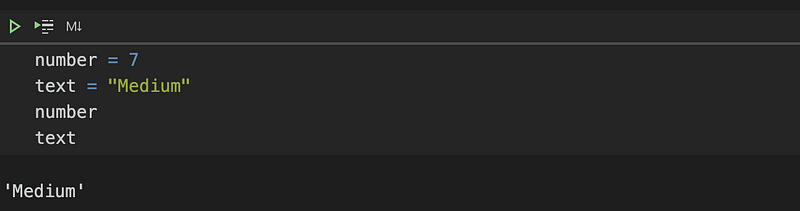
By default, a Jupyter cell prints only the last expression after execution.
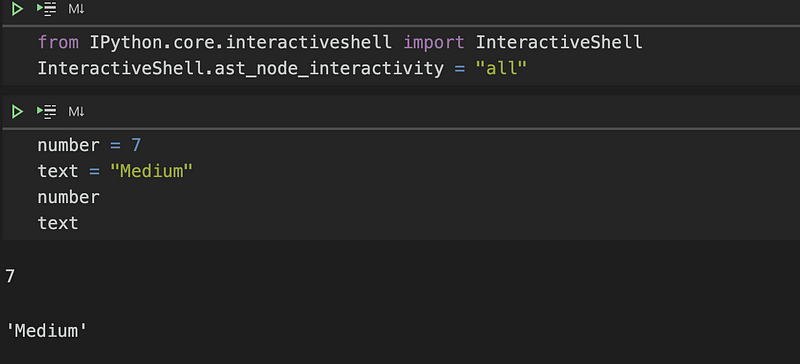
However, you might want to display multiple outputs from a single cell. You can adjust the default settings to allow for the output of all expressions.
By examining the source code of the interactive mode, you can discover additional options. For instance, you can modify the output to show either the last expression or the last assignment, which typically does not produce any output.
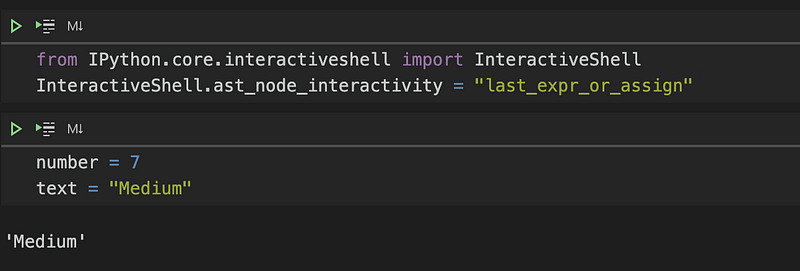
If you're interested in exploring other options, you can refer to the source code for various settings, noting that the default value is “last_expr,” which you can revert to if desired.
Conclusion
In this article, we've explored four straightforward yet powerful features of Jupyter Notebook that you can incorporate into your data science projects. There are numerous other features worth exploring, including Notebook extensions, widgets, and various magic commands, which we can delve into in upcoming discussions.
Enhance Your Data Science Skills with Video Resources
This video tutorial titled "How to use Jupyter notebooks for data analysis" provides a comprehensive overview of utilizing Jupyter Notebooks effectively for data analysis.
Additionally, check out "5 Jupyter Notebook Tips & Tricks to Improve your Data Science Workflow!" to discover practical tips that can streamline your data science processes.