Five Essential Error Analyses for ML Model Production Readiness
Written on
Chapter 1: Understanding the Importance of Error Analysis
As the deep learning revolution took off in 2012, sparked by Alex Krizhevsky’s convolutional neural network, significant advancements in image classification accuracy were achieved—over 10% improvements were observed. This success led various industries, from finance to autonomous driving, to adopt machine learning technologies to enhance their operations.
Nonetheless, the swift transition from research to real-world applications often results in overlooked gaps that are vital for success. Many organizations evaluate their machine learning models based solely on laboratory results, often focusing on superficial accuracy metrics. This can lead to substantial performance discrepancies and undetected biases when the models are deployed in real-world scenarios.
This article discusses five crucial analyses that should be conducted to ensure your machine learning models meet expectations when deployed in production.
Section 1.1: Error Analysis: A Foundational Understanding
To appreciate the unique aspects of each error analysis, it's essential to grasp the fundamental principles of machine learning models and their limitations. In traditional engineering, the goal is to design systems that accurately map inputs to outputs. However, when faced with complex, unknown systems, this task becomes challenging. This is where machine learning, particularly supervised learning, becomes invaluable. Instead of constructing a model from scratch, we learn one from existing input-output pairs.
A common practice in training and evaluating machine learning models involves splitting the dataset into training and validation subsets. The training data is used to develop the model, while the validation set serves as a benchmark for its generalization capabilities in real-world situations. Understanding the composition of these datasets and potential shifts in distribution upon deployment is critical, as all subsequent error analyses hinge on this concept.
Section 1.2: Error Analysis 1: Evaluating Dataset Size
The initial and most critical error analysis revolves around assessing whether the training and validation datasets are adequately sized. For example, consider a model designed to distinguish between cats and dogs. If the training dataset includes images of 40 dog breeds but neglects 10 others, the model may appear to perform well in a controlled environment but will struggle with unrepresented breeds in practical applications.
This scenario, while seemingly exaggerated, reflects real-world challenges where data distributions can be intricate and poorly understood. Here are some issues that arise when datasets are insufficiently sized:
- Small Training Set: A limited training dataset may not capture the variety present in real-world data, leading to overfitting.
- Small Validation Set: An overly small validation set may fail to test the model against all possible scenarios, leading to misleading performance assessments.
A general rule of thumb is that datasets comprising fewer than a few thousand samples—especially for deep learning models—are unlikely to yield satisfactory generalization.
Solution: The remedy is simple: expand your dataset. Understand the realistic scenarios your model will encounter and gather more data. Companies like Google and Facebook continuously collect vast amounts of data, recognizing the substantial benefits of larger datasets for machine learning applications.
Section 1.3: Error Analysis 2: Dataset Balance and Class Accuracy
This analysis focuses on label distribution within the dataset. For instance, if a dataset consists of 1,000 images where 990 are dogs and only 10 are cats, a model might achieve an apparent accuracy of 99% by classifying everything as a dog—an outcome that is both misleading and unhelpful.
To avoid this pitfall, it’s essential to ensure that each class is adequately represented in the dataset. Ideally, each class should have a similar number of samples, or at the very least, each class should contain a few hundred samples.
Even with a balanced dataset, performance can vary across classes. Metrics beyond simple accuracy should be employed to evaluate performance, such as:

- F1 Score: This metric balances precision and recall, particularly useful for binary classification tasks.
- Confusion Matrix: This visualization helps identify where misclassifications occur among classes.
- ROC Curve: By varying thresholds, one can determine the optimal classification point.
Solution: If one class is underrepresented or performs poorly, consider augmenting the data for that class. Techniques like data augmentation can help mitigate imbalances when real-world samples are scarce.
Chapter 2: Advanced Error Analysis Techniques
Video Description: This video explores how to identify errors, data bias, and interpretability in machine learning models using responsible AI practices.
Section 2.1: Error Analysis 3: Investigating Fine-Grained Misclassifications
Even when quantitative metrics indicate good performance, qualitative assessments can reveal underlying issues. For example, a model could excel overall but misclassify specific instances, like white cats, due to distribution differences between training and real-world data.
Solution: Address fine-grained misclassifications by augmenting the dataset with more samples of the underperforming subclasses.
Section 2.2: Error Analysis 4: Overfitting Assessment
Overfitting occurs when a model learns patterns only present in the training data, leading to poor performance on unseen data. It can manifest in two ways:
- Overfitting to the Training Set: This is evident when training loss decreases while validation loss stagnates.
- Overfitting to the Validation Set: This occurs if early stopping is based on validation performance, possibly selecting a model too tailored to the validation data.
Solution: Techniques such as early stopping, reducing model complexity, applying regularizations, using dropout layers, and data augmentation can help mitigate overfitting.
Section 2.3: Error Analysis 5: Simulating Real-World Scenarios
Finally, to ensure that a model is truly ready for production, it must be tested in scenarios that mimic its intended use. For instance, a dog/cat classification app should be tested across various camera types to verify performance consistency.
Solution: If all analyses suggest a robust model, consider deploying it with an online learning mechanism to continuously improve by incorporating new data as it becomes available.
A Case Study of Failure
To illustrate the importance of thorough error analysis, we can examine two notable failures in AI applications: Amazon’s AI recruitment tool and Facebook’s advertisement system.
Amazon AI Recruitment: In 2014, Amazon developed an AI recruitment tool that inadvertently favored male candidates due to its reliance on historical data that reflected a male-dominated workforce.
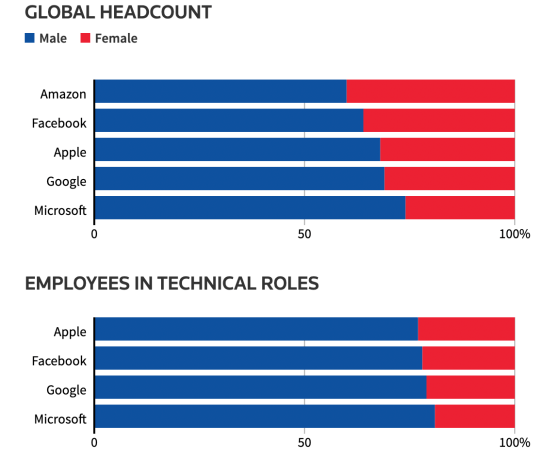
Facebook Advertising Bias: Similarly, Facebook's machine learning algorithms led to biased ad visibility, excluding women from certain ads based on general population assumptions.
Conclusion: These cases underscore the necessity for comprehensive error analysis before deploying machine learning models. By recognizing dataset balance and emulating real-world conditions, organizations can avoid significant pitfalls.
Endnote
To summarize, performing these five error analyses is essential for ensuring your machine learning model is fit for production. For further reading, consider exploring additional resources on error analysis and machine learning best practices.
Video Description: This lecture from Stanford’s CS229 course provides insights on debugging machine learning models and conducting error analysis.