Creating a Personal Crypto Alert System: A Step-by-Step Guide
Written on
Chapter 1: Introduction to Personal Crypto Alerts
If you’re anything like me, your journey into cryptocurrency started recently, just as the market seemed to plateau and stopped making headlines about overnight millionaires. Now, you find yourself anxious, fearing that you might wake up to discover your investment has plummeted in value. Unlike the stock market, which has set trading hours, cryptocurrency can fluctuate at any moment.
Wouldn't it be great to receive alerts about significant price movements without the marketing noise from exchange notifications? It seems the only solution is to create a system ourselves. Let’s dive into the project.
The Objective
The aim of this endeavor is to set up an email notification system that alerts us whenever the price of specific cryptocurrencies changes by 5% or more within a day. In the future, I may expand this to include various timeframes, multiple currencies, and different percentage thresholds. However, for our minimum viable product (MVP) and learning purposes, this straightforward goal is an excellent starting point.
Rekindling the Passion
It’s not my responsibility to rescue you; that’s up to you. As a data professional, you shouldn’t find this task overly challenging. What’s that? You’ve only worked with datasets from your job and never attempted to collect, analyze, or alert on a dataset you actually care about? That’s unfortunate. When did you stop being a dreamer?
Modern data stacks can be both costly and tedious. Allow me to guide you through the process of establishing your own Personal Data Stack, enabling you to gather and analyze whatever you desire.
To achieve this, we will:
- Retrieve the latest cryptocurrency price data from an API every five minutes.
- Run a query every hour to calculate the percentage change for a specific coin.
- Send an email alert if a significant price change occurs.
There are numerous approaches to implement this, and various design choices will impact the system's cost, maintainability, and performance. I’ll clarify my rationale behind each decision and discuss the advantages and disadvantages of alternatives.
Let’s get started!
Step 1: Data Collection
The necessary data won’t simply appear at your doorstep; you need to collect it actively. For this project, we will utilize the CryptoCompare API to obtain the latest price quotes for the cryptocurrencies we wish to monitor.
Here’s an example of how to fetch the price of four currencies (BTC, ETH, REP, DASH) using Python, transform it into a DataFrame, and store it directly in S3 using the AWS Wrangler package:

Scheduling the Script
Having a script to fetch data is fantastic, but scheduling it to run every five minutes is even better. To simplify my life, I decided to experiment with a new notebook tool called Hex. My main requirements were:
- An intuitive IDE environment
- A straightforward deployment and scheduling process
- An easy way to access historical logs
Hex mostly meets these criteria, though there are some caveats. Notably, the ability to schedule jobs (referred to as apps) is a premium feature that costs $75 per month, which is a bit high for a personal budget. Additionally, the maximum scheduling frequency is once per hour. However, with a little creativity, I managed to run the data-fetching code every five minutes by wrapping it in a loop that executes ten times with a 300-second pause.
Here’s a conceptual overview of the code:

Despite these limitations, the experience of developing and deploying Python code with Hex was quite enjoyable. Its remarkable features for SQL templating and creating DataFrames from SQL results will be covered in the Alerter notebook section.
To see the deployed script in the Hex app, click here!
Dealing with Small File Issues Using Delta Lake
Once the data retrieval script is operational, we’ll start to accumulate objects in S3.
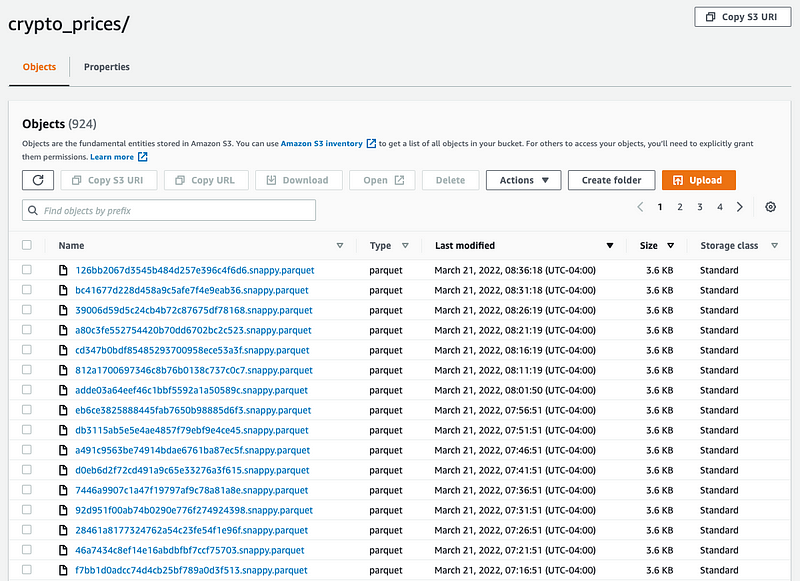
While this is exciting, generating numerous small files can hinder query performance. This is a common challenge in object stores; we must manage these objects to ensure optimal performance. I have worked at companies that addressed this issue internally by implementing a Compaction Service, which ran Spark jobs to consolidate small files into larger ones. However, I do not recommend this approach.
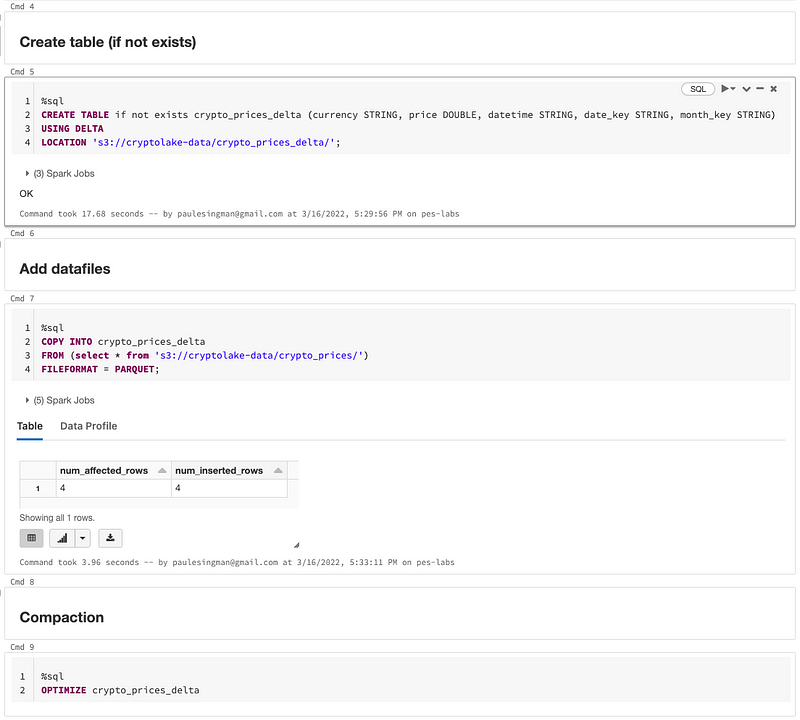
Instead, I will utilize technologies designed to tackle this challenge, specifically Databricks' COPY INTO command to import data files into a Delta Lake table, followed by the OPTIMIZE command to compact them.
Here’s a screenshot of the commands I run as a Databricks Job every hour to maintain an optimized Delta table:
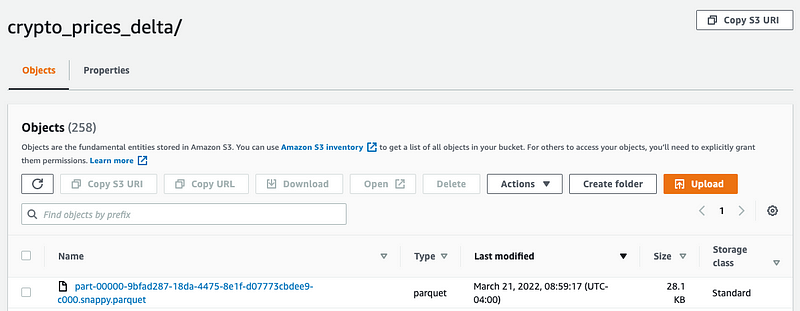
Now we have a single, larger file in the Delta Table, significantly improving performance for analysis as the original dataset grows to thousands, and eventually millions, of files.
Analyzing and Alerting on the Delta Table
After refreshing my SQL skills, I successfully wrote a query to calculate the daily percentage change from the crypto_prices_delta table:
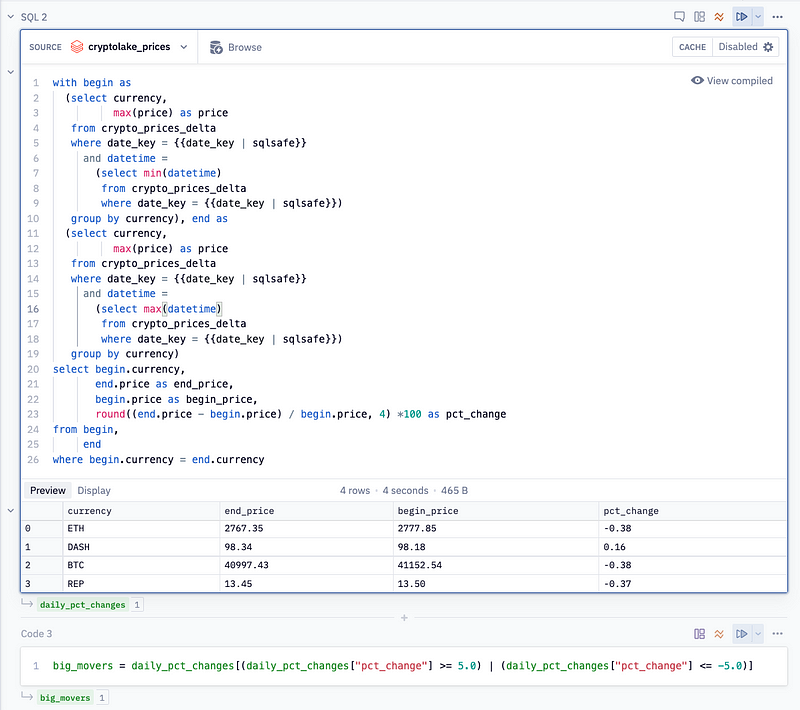
The final step is to run this query regularly to trigger alerts. Occasionally, the universe aligns with your objectives, and unexpected opportunities arise. For this project, that was the recent partnership announcement between Hex and Databricks, allowing you to configure a Databricks SQL endpoint as a data source in Hex.
After setting up the SQL Endpoint in Databricks and creating a data source in Hex, I was able to write queries against it. Two features in Hex made the experience enjoyable: SQL parameterization and DataFrame SQL. SQL parameterization allowed me to define today’s date in Python and incorporate it into my query using Jinja syntax. DataFrame SQL lets you execute a query and automatically transform the results into a Pandas DataFrame. After calculating the daily percentage change, I filtered the results to show only those exceeding a 5% change.
Here’s a preview of the Hex notebook:
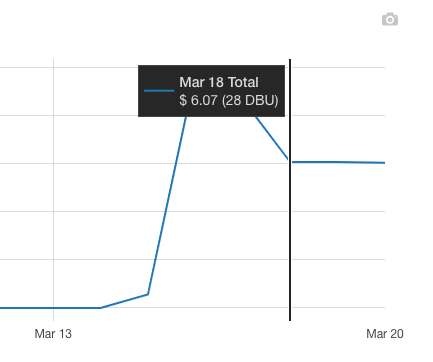
Awesome! The final step involved raising an exception in the big_movers DataFrame if it contained any rows. I then scheduled the Hex notebook as an App to send an email alert to my inbox if it failed. Click here to view the complete notebook in Hex!
Looking Ahead
There are numerous ways to enhance this pipeline, starting with the additional flexibilities mentioned earlier. Nevertheless, I’m pleased that I was able to create a functional solution without managing any services myself and at a reasonable cost.
In terms of expenses, this setup costs around $12 daily for AWS, with an additional $6 for the Compaction Job and SQL Endpoint on Databricks.
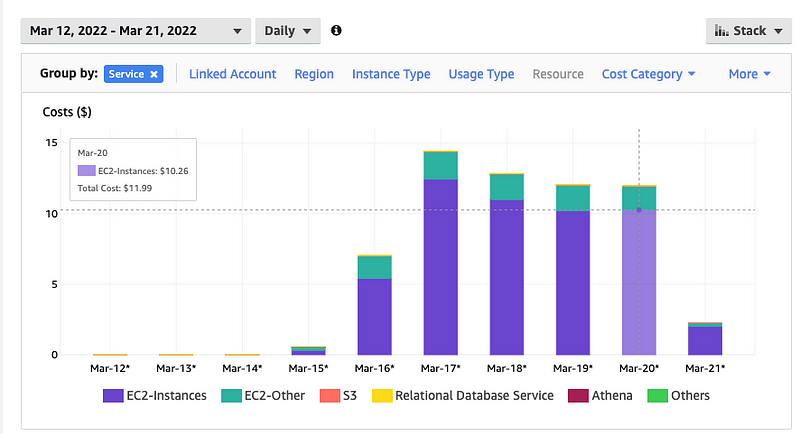
When viewed in this light, $2.5 per day for Hex seems reasonable, although it’s tempting to consider alternatives that are free or self-hosted.
Thanks for reading! If you found this article valuable, consider following me on Twitter for future updates. I welcome your thoughts and comments below!
Chapter 2: Practical Video Tutorials
In this tutorial, learn how to create a cryptocurrency price tracking application using React JS and the CoinGecko API step by step.
Discover how to deploy your custom trading strategy without writing code by utilizing ChatGPT on Delta Exchange in India.